Let's Take a Baby Step into Machine Learning
- Saarthak Sangamnerkar

- Aug 30, 2018
- 9 min read
Updated: Sep 1, 2018
Let's dive into the enticing field of Machine Learning, understand some of the basic concepts and see why it is so talked about in the Silicon Valley
The Chief Executive Officer of Intel, Brian Krzanich, once said in an interview, "Data is the new oil." It was a pretty gigantic statement coming from the CEO, of course. Data is being generated at an unprecedented rate nowadays. Over 2.5 quintillion bytes of data is being generated every frigging day. Ninety percent of the data has been generated in last two years alone. These are absolutely mind boggling figures. With the rapid advancement in Internet of Things, the rate is just going to increase.
So I felt that this is high time to learn how to tackle this "problem of plenty" and with a mindset to make a career out of it. It was May 2017 when this thought had struck me for the first time. I started with that famous Machine Learning course by Andrew Ng, but soon I realized I wasn't ready then. I had to brush my fundamentals a bit more. To be honest, Data and Machine Learning seemed very boring back then and never felt like something which I would love to do daily. Fast forward one year, I have a totally different view. Data Science and Machine Learning are some things which just never leave my mind anymore. The specialization on Applied Data Science offered by University of Michigan on Coursera is really a fantastic resource to start your journey into the powerful world of Data Science and Machine Learning.
I want to make a note in the beginning itself. This blog post is not a tutorial but an exploratory article. For my readers who are interested, I will post the links of tutorials and guides for Data Science and Machine Learning in the Resources section at the end of this article.
Machine Learning - That Famous Definition
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E. — Tom Mitchell
So if you want your program to predict, for example, traffic patterns at a busy intersection (task T), you can run it through a machine learning algorithm with data about past traffic patterns (experience E) and, if it has successfully “learned”, it will then do better at predicting future traffic patterns (performance measure P).
So, what is Machine Learning?

Machine Learning is a driving force for Artificial Intelligence. Computers can learn on their own from their past experience and there is no need to explicitly program the machine when the machine faces a new dataset. The machine self-learns and grows in experience and in performance, as well.
Machine learning is a method of data analysis that automates analytical model building. - SAS
The definition stated by the Carolina based software development firm, SAS, simply means that Machine Learning allows computers to analyze data to find meaningful information without the need of being programmed where to look for data but rather by developing some sort of generalized algorithm which would iteratively learn about the training model.
The field of Machine Learning may have been gaining rapid momentum for past few years but actually, the domain dates back to Alan Turing's Enigma Machine during World War II.
There are lots of different machine algorithms because it is practically impossible to design algorithms to fit a broader real life purpose. These algorithms are broadly classified into two categories:
1. Supervised Machine Learning: The program is “trained” on a pre-defined set of “training examples”, which then facilitate its ability to reach an accurate conclusion when given new data.
2. Unsupervised Machine Learning: The program is given a bunch of data and must find patterns and relationships therein.
Supervised Machine Learning

Supervised Learning is a category of Machine Learning algorithms that uses a known dataset to make predictions. The known dataset is referred to as training set. The training dataset includes input data and response values. The goal of supervised algorithms is to map the input data with corresponding response values in order to build a model that can predict reponse values if unseen dataset is fed into the algorithm. The larger the training set is, more generalize the reponse set is for a new dataset and higher is its predictive capability.
Regression
Regression is a technique used to model and analyze the relationships between variables and often times how they contribute and are related to producing a particular outcome together. This method is mostly used for forecasting and finding out cause and effect relationship between variables. Regression techniques mostly differ based on the number of independent variables and the type of relationship between the independent and dependent variables.
For example consider you have to predict the income of a person, based on the given input data X. Here, target variable means the unknown variable we care about predicting, and continuous means there aren’t gaps(discontinuities) in the value that Y can take on. Predicting income is a classic regression problem. Your input data should have all the information (known as features) about the individual that can predict income such as his working hours, education experience, job title, a place he lives.
In the majority of supervised learning applications, the ultimate goal is to develop a finely tuned predictor function h(x) (sometimes called the “hypothesis”). “Learning” consists of using sophisticated mathematical algorithms to optimize this function so that, given input data x about a certain domain (say, square footage of a house), it will accurately predict some interesting value h(x) (say, market price for said house). In practice, x almost always represents multiple data points. So, for example, a housing price predictor might take not only square-footage (x1) but also number of bedrooms (x2), number of bathrooms (x3), number of floors (x4), year built (x5), zip code (x6), and so forth. Determining which inputs to use is an important part of ML design. However, for the sake of explanation, it is easiest to assume a single input value is used.
So let’s say our simple predictor has this form:
where θ_0 and θ_1 are constants. Our goal is to find the perfect values of θ_0 and θ_1 to make our predictor work as well as possible.
Optimizing the predictor h(x) is done using training examples. For each training example, we have an input value x_train, for which a corresponding output, y, is known in advance. For each example, we find the difference between the known, correct value y, and our predicted value h(x_train). With enough training examples, these differences give us a useful way to measure the “wrongness” of h(x). We can then tweak h(x) by tweaking the values of θ_0 and θ_1 to make it “less wrong”. This process is repeated over and over until the system has converged on the best values for θ_0 and θ_1. In this way, the predictor becomes trained, and is ready to do some real-world predicting.
A Simple Example
Generally, Machine Learning algorithms work with a dataset of million dimensions but for the sake of understanding, let us take a simple example. We will take a dataset of employees of a company who have rated their satisfaction on a scale of 1-100.

Looking at the above graph, one thing is very obvious, there is a pattern. The satisfaction rating goes up as the salary increases. But still, it is necessary to observe that the data is noisy. All points can not be plotted on one straight line. As an aspiring Machine Learning engineer, you should understand this very quickly - real world data will always be noisy. So then the question arises how to train the machine using the real world dataset to accurately predict an employee's satisfaction level? The quick answer is NO, we can't. Machine Learning never aspires to be perfect. In fact, the domains where Machine Learning is applied does not really have what you call as "perfect". The purpose of applying Machine Learning is to get as close to perfection as you can possibly can.
All models are wrong, but some are useful. - George E.P. Box, British statistician and Mathematician
So let us start working on the dataset we have given to our machine using which we got the above plot. It's now time to give some reasonable value to θ_0 and θ_1 and thus, initialize our hypothesis function h(x).
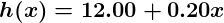
We have given θ_0 a value of 12.00 and set θ_1 equal to 0.20. Let us see the plot now.

Of course, this machine performed terribly. We need to set some other values for θ_0 and θ_1. But the question remains, we can't sit and put in every frigging value and plot to see which performed the best. Using a bit of mathematics (which I will explain to you shortly), we can close in to give values of 13.12 and 0.61 for θ_0 and θ_1 respectively.

Let us see the plot for this hypothesis.

Getting closer right? Now if we repeat the mathematical process for 1500 times, the hypothesis will end up looking like this:

Let us plot the operations.

We find that after a number of times, θ_0 and θ_1 won't change by any significant amount. We may, thus, say that the system has "converged". If we now ask the machine again for the satisfaction rating of the employee who makes $60,000, it will predict a rating of roughly 60.

We can now safely say we have found an optimum function for the above problem.
Complexity in Regression
The example that we saw just now was basically an example of linear regression with one variable or in more fancier terms, univariate linear regression. Normal equations can be derived to find the solutions to a univariate linear regression pretty easily.
Now, consider this hypothesis function:

This is a four dimensional function with a number of different polynomial terms. It is a real difficult task to solve this predictor by deriving a normal equation. But to be real, this predictor function has got just four dimensions. A real world dataset may be million dimensional with hundreds of coefficient. For eg, predicting the climate of fifty years from now or expressing an organism's genome are a few complex examples which can't be solved by deriving a normal equation.
However, there is a way out of this. Machine Learning algorithm, as some data scientists like to say, "feel its way" to the solution rather than just iterative brute force. This way makes Machine Learning incredibly flexible and at the same time, really powerful. So let us talk about how a Machine Learning algorithm "feel its way" out.
Gradient Descent
Gradient Descent is an optimization algorithm to find the coefficient in order to minimize the hypothesis function to its local minimum. You start by defining the initial parameters values and from there on Gradient Descent iteratively adjusts the values, using calculus, so that they minimize the given cost-function.
Intuition: Consider the 3-dimensional graph below in the context of a cost function. Our goal is to move from the mountain in the top right corner (high cost) to the dark blue sea in the bottom left (low cost). The arrows represent the direction of steepest descent (negative gradient) from any given point–the direction that decreases the cost function as quickly as possible.

Starting at the top of the mountain, we take our first step downhill in the direction specified by the negative gradient. Next we recalculate the negative gradient (passing in the coordinates of our new point) and take another step in the direction it specifies. We continue this process iteratively until we get to the bottom of our graph, or to a point where we can no longer move downhill–a local minimum.

Classification
In machine learning and statistics, classification is a supervised learning approach in which the computer program learns from the data input given to it and then uses this learning to classify new observation. This data set may simply be bi-class (like identifying whether the person is male or female or that the mail is spam or non-spam) or it may be multi-class too. Some examples of classification problems are: speech recognition, handwriting recognition, bio metric identification, document classification etc. It is a two-step process, consisting of a learning step and a classification step.
For example, consider the example of a medical researcher who wants to analyze breast cancer data to predict which one in three specific treatments a patient should receive. This data analysis task is called Classification, where a model or classifier is constructed to predict class labels, such as “treatment A,” “treatment B” or “treatment C.”
Unsupervised Machine Learning

Unsupervised machine learning algorithms infer patterns from a dataset without reference to known, or labeled, outcomes. Unlike supervised machine learning, unsupervised machine learning methods cannot be directly applied to a regression or a classification problem because you have no idea what the values for the output data might be, making it impossible for you to train the algorithm the way you normally would. Unsupervised learning can instead be used for discovering the underlying structure of the data.
The best time to use unsupervised machine learning is when you don’t have data on desired outcomes, like determining a target market for an entirely new product that your business has never sold before. However, if you are trying to get a better understanding of your existing consumer base, supervised learning is the optimal technique.
Some applications of unsupervised machine learning techniques include:
Clustering allows you to automatically split the dataset into groups according to similarity. Often, however, cluster analysis overestimates the similarity between groups and doesn’t treat data points as individuals. For this reason, cluster analysis is a poor choice for applications like customer segmentation and targeting.
Anomaly detection can automatically discover unusual data points in your dataset. This is useful in pinpointing fraudulent transactions, discovering faulty pieces of hardware, or identifying an outlier caused by a human error during data entry.
Association mining identifies sets of items that frequently occur together in your dataset. Retailers often use it for basket analysis, because it allows analysts to discover goods often purchased at the same time and develop more effective marketing and merchandising strategies.
Latent variable models are commonly used for data preprocessing, such as reducing the number of features in a dataset (dimensionality reduction) or decomposing the dataset into multiple components.
So, this article has explored a lot of machine learning basics but a note of caution: we have barely scratched a surface yet. Don't get excited just yet. There's a long road ahead. There is a lot more to learn. A lot of topics discussed in this article will be explored in depth along with more examples, mathematics and coding in their own dedicated blog article. Tighten your seat belts because the road ahead is very thrilling. Till then, ta-ta!
Further Reading
1. https://www.sas.com/en_us/insights/analytics/machine-learning.html
2. https://towardsdatascience.com/machine-learning/home
3. https://www.coursera.org/learn/machine-learning
4. https://in.mathworks.com/discovery/machine-learning.html


Comments